好了,現在總該告訴我甚麼是型別了吧?
型別就是用來告訴你資料應該儲存並顯示成甚麼樣子
還記得之前我們寫C/C++的時候嗎?
input-'0';
我們使用了字元的加減
到底為甚麼字元可以加減?
理由在於資料儲存的方式都是數字(電腦是認不得文字的,他只認識0跟1)
只是因為你宣告了他的型別是字元,因此當你使用cout顯示他時會顯示字元
所以當你對字元加減時,其實是對他的資料進行加減
這裡我們稍微提一下資料的最小單位
byte
也就是我們在電腦看到的B,KB,MB,GB的B
他是由八個bit組成
還記得以前學過物質的最小單位是原子嗎?
原子是可以表現化學特性的最小單位
但是原子還是可以進行分割成質子,但是質子並沒有可以展現的化學特性
就如同最小的bit並不能代表任何資料
最小可以代表資料的單位是byte
而一個byte也就是8個bits可以儲存多大的資料呢?
由於一個bit只能放置1或是0
因此八個bits可以從00000000放到11111111,也就是0~255(二進制跟十進制的關係)
這時由於C/C++的字元是採用ASCII編碼
因此當你使用
char test = 'a'
時候
他會去找'a'相對應的ASCII碼,並儲存於叫做test的變數內
因此test裡面儲存的並不是'a'而是97這個數值
而儲存97這個數值在byte的資料就是
0110 0001
因此當你使用
'a' - '0'
時
其實是
0110 0001 - 0011 0000
0011 0000 是'0'這個字元的ASCII碼
其他語言沒辦法這麼做是因為其他語言已經將字元給另外處理過了,但C/C++就如同手排車一樣,他預設你知道資料實際上長甚麼樣子,因此他讓你去相減裡面的資料
而其他語言則讓你可以不用了解資料長甚麼樣子,而是由程式語言去幫你處理
所以一個字元有多大?
就是一個byte
在ASCII裡面一個byte所能表示的0~255就是對照ASCII的0~255
也就是說一個byte剛好能表示所有的字元
而C/C++怎麼知道這個儲存的資料是01100001(97)還是'a'呢?
就是靠你剛才告訴他的型別
因此型別特別重要,他告訴了程式語言該怎麼處理這筆資料
剛才我們介紹的字元其實是型別的其中一種
而型別到底有幾種則要看程式語言怎麼設計的
像是javascript就沒有字元型別,只有字串
而C則沒有字串型別,只有字元,如果你需要字串必須使用字元陣列
以下我們以C#來介紹
如果你沒有打算學C#我也會建議你往下看,因為C#在型別定義方面比大部分語言都還要多
因此你只會多學,不會少學
C#的型別大致上可以分成五種
以下我們逐一介紹
在C#內整數又可以分成以下幾種
| 型別 | 大小 | 容許值 |
|---|---|---|
| byte | 8bit | 0 到 255 |
| sbyte | 8bit | -128 到 127 |
| short | 16bit | -32,768 到 32,767 |
| ushort | 16bit | 0 到 65,535 |
| int | 32bit | -2147483648 到 2147483647 |
| uint | 32bit | 0 到 4,294,967,295 |
| long | 64bit | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 |
| ulong | 64bit | 0 到 18,446,744,073,709,551,615 |
注意C#的byte是一個型別而不是電腦常見的資料大小喔
而我們之前用過的int其實有4byte也就是64bits這麼大
為甚麼整數要區分這麼多種?
這是為了讓你掌控資料的儲存空間
如果你今天只想宣告一個5的數值,但是你宣告他的型別為long或ulong
他會幫你保留8byte也就是32bits的大小,即便你用不到他
會這麼保留的原因是因為記憶體是連續的

因此當今天你想要放入一個型別為int的數值時
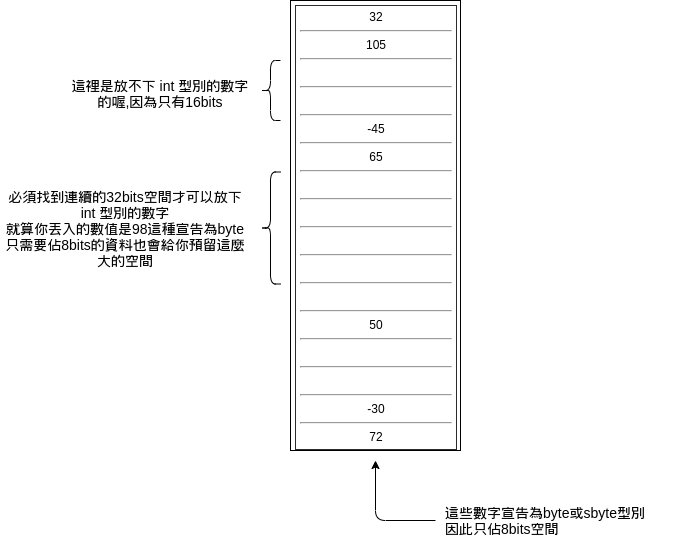
程式會自動保留一大塊讓你存取這個變數
所以如果你其實沒用到這麼大的數值,那就沒有必要為他預設這麼大的空間
否則你的程式執行起來會相當的占記憶體
注意有些型別長相類似但是前面有加前綴
這是因為要區分這個數值是否為負數
儲存方式類似
0000 1111 //表示15
1000 1111 //表示-241
為啥不是-15阿?
這個講起來超複雜
實際上要算要使用15-256
理由可以看中山大學楊昌彪教授的youtube,點我前往
注意,實際上在每個語言作法並不相同,只是在這裡剛好是這樣
因此看到如果要表示負數,會將前面第一個bit的0跟1來表示正數或負數
而
1111 1111
代表的是256還是-1
則要靠你宣告給他的型別
如果是byte表示只有正數,此時就會是256
而sbyte則因為有負數,因此1111 1111就會是-1
有個有趣的地方是,如果將1111 1111加上1會變得如何?
1 0000 0000
此時最左邊的1將會溢位,也就是直接消失,然後這個數就變成0了
是不是有點了解為什麼1000 1111 不是直接代表負的 0000 1111了呢?
這是為了保證加減法的一致性
於是乎1000 0000 就變成最小的數值-128,然後一路往上加,直到變成1111 1111也就是-1
short的大小為16bits
因此他的儲存方式為 0000 0000 0000 0000
而ushort,表示unsign的short,也就是前面沒有加符號的short
因此ushort只會有0跟正數
其他整數型別雷同
C#的字串分成兩種
C#的字元採用utf-16標準而不是ASCII
utf16是以16個bits為編碼空間
因此他的字元大小為16bits
為甚麼跟C/C++的ASCII編碼不一樣?
理由在於ASCII只能顯示大小寫字母跟一些常用符號,沒辦法顯示其他文字(比方說中文)
因此C#在設計時就採用utf-16讓他的字元可以顯示更多種文字
那為甚麼C/C++不採用utf-16?
因為C/C++誕生的時候utf-16還沒有出來
所以如果你要知道程式底層在做的事情,你必須要知道他的資料型態跟採用的標準
而C#的字串則會動態改變大小
多大取決於裡面的字串有多長
至於記憶體位置怎麼放,放哪裡,如何規劃,都是由C#幫你決定
就如同自排車,會自動幫你換檔
C/C++就像是手排車,你必須自己規劃記憶體大小
布林型別只有兩種值
這裡指的是值的種類而不是型別的種類
如同你在int可以放1,15,93之類的值
bool則可以放true或false
bool代表型別,true跟false表示值
在某些語言中(比方說C/C++或jabvascript)整數1跟0可以轉換成bool型別
但是C#中不行
這是因為每個語言設計的理念不同
布林值是用來代表是或否,比方說你可以這樣寫
var check = true; //這裡宣告了一個布林值為true的變數
if (check == true){
Console.WriteLine("check!");
}
可以用來當作一個旗標,當你的check設置為false時就不會印出check!
浮點數是具有小數點的數值型別
分成以下幾種
| 型別 | 大小 | 容許值 | 精度位數 |
|---|---|---|---|
| float | 4byte | ±1.5 x 10^−45 到 ±3.4 x 10^38 | ~6-9 位數 |
| double | 8byte | ±5.0 × 10^−324 至 ±1.7 × 10^308 | ~15-17 位數 |
| decimal | 16byte | ±1.0 x 10^-28 到 ±7.9228 x 10^28 | 28-29 位數 |
C#的浮點數就沒有sign跟unsign之分了,通通都有正負號
使用浮點數的理由是如果今天儲存的數值相當的大
比方說2000000000000000
之類的,就會因為轉成二進制後整個數字變得相當的長而佔用到相當多的空間
因此會將其轉成指數的寫法
2*10^15
將冪次與底數分開做儲存的動作
也因為如此浮點數可以用來做具有小數點的數值的儲存方式
我們先來看看最小的float長什麼樣子

這裡的底數為二進制的1.00011110000111100001111
最前面的1.是自動補上的
因此浮點數的底數會在1~2之間
一定嗎?
一定
理由在於科學記號的表達式
當你要用科學記號表達900時會怎麼寫?
9 * 10^2
而不是寫成
0.9 * 10^3
或是
90 * 10^1
對吧
因為科學記號的實數部必只能有一位,並且此位不能是0
所以由二進制表達的科學記號實數部一定會在1~2之間
(二進制不能有1跟0以外的字,科學記號表達式讓他不能為0)
指數則是二進制的10000010(也就是130)減去十進制的127(理由是C#會拿0~126去做其他的事)
也就是3次方
最終計算會變成
1.00011110000111100001111 x 2 ^ 3
也就是
8.00088880000888800008888
讓我們反過來計算浮點數的8.0會如何儲存吧
首先先將8換算成2進制,也就是1000
換算後得到
1.0 x 2^3
將3加上127就會變成我們要的冪次130(看成二進制就是10000010)
之後補上1.0的小數點後面位數(全部都是0)
最後在前面補上正負號(這裡是正數,所以為0)
就會變成
0100 0001 0000 0000 0000 0000 0000 0000
你們可以到這裡玩玩
但是浮點數也不是沒有問題,因為是使用二進制來計算十進制的小數點,
因此在某些數值上可能會有誤差
比方說你在上面的計算輸入內輸入12.345這種難以換算成二進制的數值就沒辦法剛好算成12.345
為此提出的解決方案就是加長
將原本的4byte加長到8byte(就是加倍,所以他的名字才叫double)
冪次同樣用8bits,因此後面的小數點位數就可以來到52位
有時候你不會看到double這個名字,而是看到float64跟float32
就是指64bits的浮點數跟32bits的浮點數
而decimal則是C#提供給金融或科學運算需要極大或極小值時使用的(反正就是繼續加長就對了)
null想表達的最終意含為
我存在,但是值不存在
舉個簡單的例子,你今天宣告一個型別為bool的變數時,就算一開始沒有給他值也會預設是false
但是你不想這麼快就定義他的值,因為其他的計算式還沒完成,這時直接定義為false可能會讓其他部份的程式產生問題
這種情況下你就可以這麼宣告
bool? passed = null;
加上?就可以先放一個null進去,代表值尚未定義
所以我定義了一個沒有值的變數?
沒錯,你可以在瀏覽器的console試試下面的程式碼
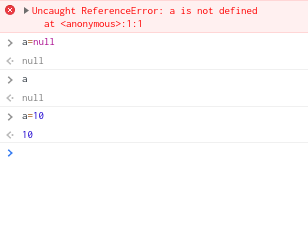
當你尚未宣告a,卻直接在console內打上a時,js的直譯器會告訴你not defined,也就是尚未定義的意思
但是當你給他了一個null時,你已經定義了a這個變數,引此之後你再度在console內打上a並不會告訴你尚未定義
只會告訴你裡面沒有值
這種情況很常用於物件上,在你為物件寫藍圖時(也就是寫class檔時)
因為你還不知道使用者會讓入什麼值,或是使用者什麼時候會把值放進去,所以可以先宣告出來,然後放入null
代表你已經可以使用這個變數了,但是裡面是空的
當然,不只是布林可以這樣宣告,在C#裡面還有這些型別可以放入null
double? a = null;
char? b = null;
int? c =null;
String d = null; //字串可以不用特地宣告就放入null
String可以不用特地操作就放入null的理由在於String在C#裡面算是參考型別
(我們之後介紹值型別與參考型別的差異)
注意,一個型別可不可以放入null在每個語言都不一樣,像是golang就不能指定字串為null
另外在字串裡面空值""跟null是完全不同的喔
同樣的你可以在瀏覽器的console裡面這樣試
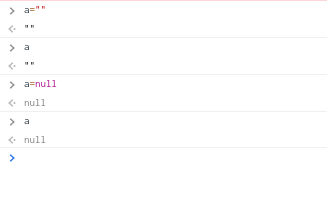
注意當你在a裡面放入""時,其實已經將值給他了,只是裡面沒東西
但是null則是告訴他裡面沒有值
以上就是對於型別的基本介紹
型別這個系統還有許多的特性,如果有興趣的人可以繼續往下研究
很多教學都習慣把型別放在前幾堂課,實際上就是為了讓學習者在操作語言時減少踩到坑的機會
但是在我前面的教學都已經把能避的坑都避掉了
這篇回來講型別的用意是當課程逐漸步入尾聲,準備要放手讓學員去飛前的幾句叮嚀
希望你們以後在學習語言時可以先去研究每種語言的型別
畢竟語言的語法只是這個語言的外觀,而真正表現語言特性的是內層處理資料的方式
如果有任何寫不清楚或是觀念沒有很明白的話請留言告知我
會盡快補上
如果有任何寫錯的地方也麻煩留言告知我
會盡快修正
感謝各位


 iThome鐵人賽
iThome鐵人賽